




Through a very wide lens, Emergent Topographies is a video installation and a collaborative digital artwork that deals with current clinical elements of the spatiotemporal ecosystem of data objects, topographically demonstrated through geodata and biodata examined by artificial intelligence.
The artwork explores the artistic applications of artificial intelligence, specifically using a generative adversarial network (GAN). The data that is generated is ultimately illustrated using an agent-based behavioral algorithm to visualize the morphing behavior using the mapping aesthetic of a connectome.
Concept
Emergent Topographies is grounded within the territorial context of the Arabian Peninsula, where, for centuries, the inhabitants have simultaneously designed and been designed by their context. From caves and mud-brick constructions to urban environments and high-tech, highly dense modern urban conglomerations, the culture has not just shaped the context; it has been progressively shaped by it. Hence, the two main interactors are context – represented as topography – and culture – represented as brain activity data.
Gradually constructing the anthroposphere, the context/culture amalgam becomes a necessary space for exploration within an increasingly hybrid world. GAN-generated topographies that encode electroencephalography (EEG) data are produced as future topographies, of human and machine in significant contextual coexistence.
Cultural progress always happens within the available technosphere and frequently expands it. Technologies, such as fire, stone hunting instruments, or borrowing other animals’ fur have gradually channeled human evolution physiologically and socially. In parallel, the physical context – i.e., the land, with all its features – has had a humongous impact on its inhabitants’ social patterns, diets, behavioral norms and culture. In turn, by expanding their technosphere, civilizations have been able to give form to new contexts, which they inhabit.
Intelligence, be it biological or mineral, is at the core of a great number of the current scientific and interdisciplinary endeavors. In this project, it is also the main topic at stake: Emergent Topographies rounds up the central role of artificial intelligence and neurotechnology (namely EEG) as a way to reinterpret silicon topologies from the Arabian peninsula. Two main data objects have been used as inputs for the process at different stages.
Geodata
Geographic Information System (GIS) Data is collected from random coordinate locations within the Arabian Peninsula and mapped as the first and core data object for the work. The data collected was mapped topologically and textured for further exploration, while maintaining a topographical three-dimensional representation as an output. Working on several representation methods throughout the process, data has been compressed to grey-scale two-dimensional depth maps, simple arrays of point cloud coordinates, and axonometric visualizations.

Biodata
Intelligence has been an object of wonder since the dawn of civilization, with the brain at the center. Almost a century ago, science had the first electrical encounters with the brain; now, consumer-grade neurotechnology enables mass usage of accessible hardware and software capable of grasping the brain’s electrical activity. Along these lines, and to bring the topic to the table, the artwork injects EEG data from a daydreaming individual as a mutational vector to generate hybridized topographies.
Bidirectional mutation
Bidirectional mutation is a well-known concept within neuroscience, accurately illustrated by the river analogy. The animal brain – the human brain, in this case – is a complex physical object that undergoes constant change. Our brains have the capacity to be rewired based on several parameters, such as the input channeling in through the sensory gateways to our perceptual machine. The process through which the brain’s capacity grows and reorganizes trans-scalarly, from very few neurons to large cortical remapping, is referred to as neuroplasticity.
Going back to the river analogy, there are two objects to be examined: the riverbank, the physical riverbed or the channel; and the water flowing. The riverbank dictates the stream’s motion, while the stream itself changes the physical channel through its forces. This process is known as meandering.
The brain and neurons are analogous to the physical channel of the river, while brain activity is analogous to the stream of water flowing. Both are in a state of bidirectional mutation, coming back to the interaction between context and culture, and why brain data has been key within the artwork.

Meandering River
Aesthetic
The brain connectome, otherwise known as the brain wiring diagram, is a comprehensive mapping of the neural connections. The figure below shows a sample model of a fly’s connectome, where wiring is color-coded and modeled accordingly. The final artwork is a higher-level representation of the GAN-generated data, recruiting an agent-based system that navigates the three-dimensional space of a point cloud of stacked hallucinated topographies, visualizing all the connections that are made.
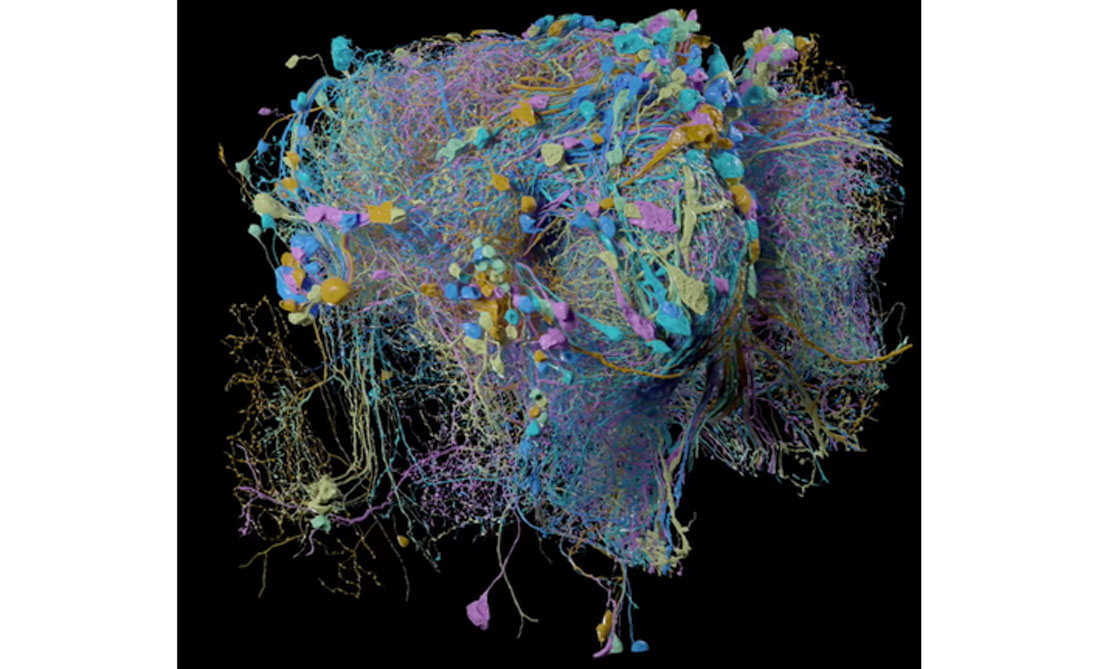
The new ‘connectome’ maps some 25,000 neurons in a fruit fly’s brain a portion of which is shown here. Image: Google / FlyEM
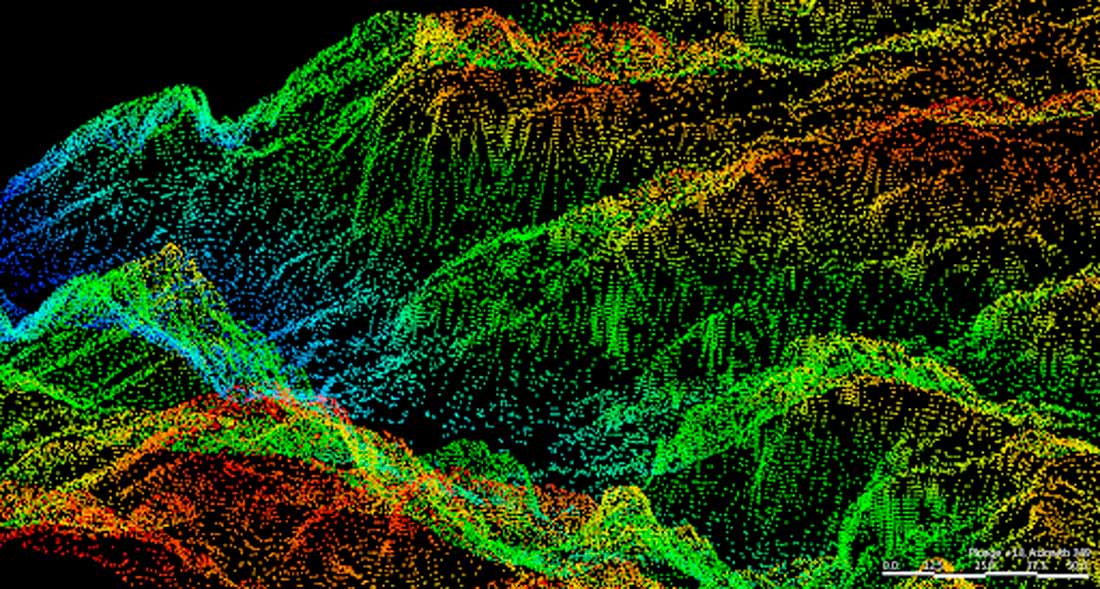
Jun Cowan, Original LIDAR point data. 23
Process
The process involves three main work packages: firstly, gathering, and systematically preparing the datasets; second, GAN; and third, agent simulation to generate the final artwork. On a closer look, the process involves [1] Collection of GIS Data, [2] Visualization and digital simulation of geodata, [3] Collection of EEG data, [4] Data compression and exploration in possible input forms and dataset formats, [5] Style-GAN training and generation of topographies, [6] Stacking generated topographies [7] Using the stacked topographies as a point cloud for an agent-based simulation while [8] Maintaining trails and connection, using connectome aesthetics
Generative Models
Generative models are statistical models capable of learning to create data similar to the input data, at a complex level. The intention behind using such models is to be able to generate high-quality images or write sophisticated poems for example. In that case, we deduce that the model has also learned a lot about the data in general. Technically, this means the models have a good representation of the data which could then be integrated into various applications, such as generating art, or pre-training neural networks if labeling data is expensive.
Since there is a tremendous amount of information in formats such as text, images, audio, and videos, the need to develop models that can analyze and understand this data is crucial. Within this project, generative models are used to generate data that is equally valid to the input stream after internally extracting its essence.
Generative Adversarial Networks [GAN]
GANs have emerged as a new deep generative models; a new method of generative networks that builds on deep learning. Image making, especially using GANs, tops the list of the most popular and successful uses of DGMs. The main operation here is sampling from the “latent space”, explained below. Sampling points from latent space and mapping them to the image space generates images that have never been seen before. Completely fake, yet possessing all that it takes to be real. Within Emergent Topographies the GAN was applied in the generative process of creating the material (topographies infused with a dream factor) to be illustrated artistically using a classical AI agent system.
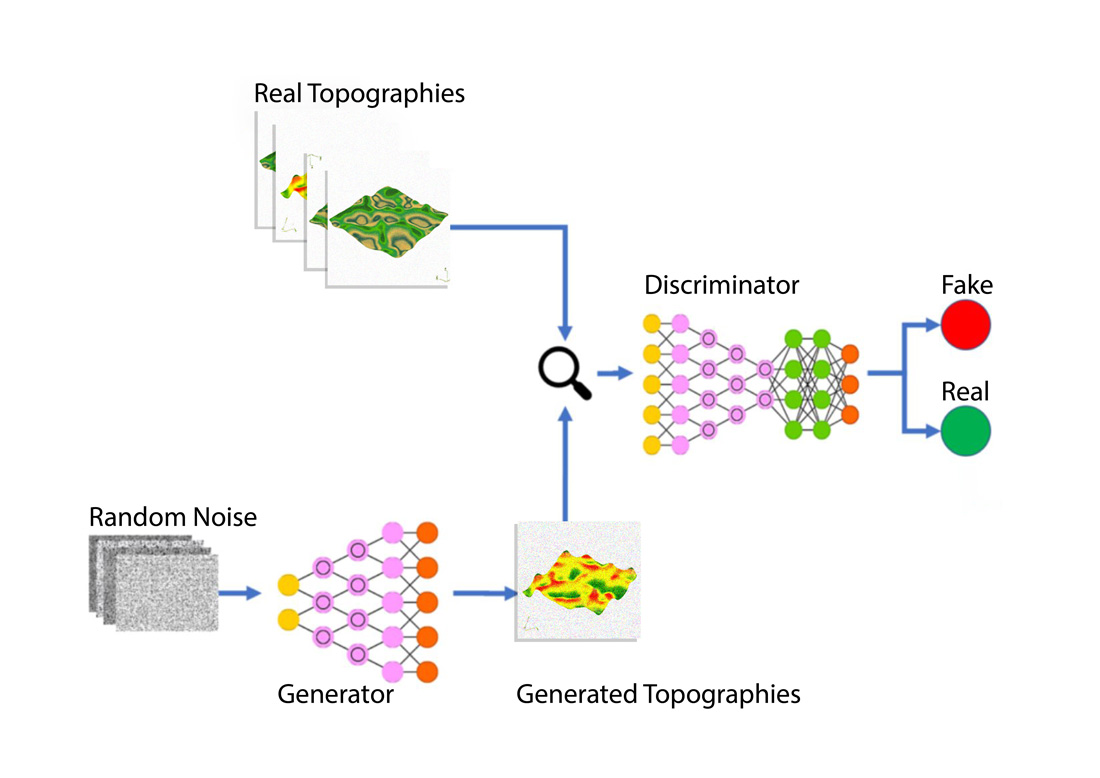
A GAN is made up of two main networks:
· The Generator Network: taking a random vector from the latent space and translating it to a synthetic image.
· The Discriminator Network: taking an image as an input and deciding whether the image came from the training dataset or from the generator.
Throughout the process, at an advanced stage, the network is able to produce “fake images” that have “real” qualifications: that is, they qualify as real images.
Below is a brief demonstration of the real images from the input data set and the fake images generated by the network.
Reals

Fakes

The end goal for the generator is to fool the discriminator by generating artificial images that look real, based on images it trained on. The end result is images that are indistinguishable from real ones.
Latent Space
Latent space is a space of representations (or vector spaces), where any point can be mapped to our data. For example, we can take an image, encode it, and represent it as a latent point in this space. One way to think about it is through “compression”. For instance, we can compress a 28x28x1-pixel image into a 3×1 vector that stores only the relevant information in it (real representation of data). This process is called encoding, while mapping a point from latent space to its real data is called decoding.
The project capitalizes on latent space, which is a very important part in GANs. Emergent Topographies dwells on the key idea of introducing the EEG data of a daydreaming individual into the generative model, injecting and mixing it with the truncation psi to sample images from the latent space itself. The use of latent space in this project will be expanded on more when we explain the truncation trick later in this article.
With the invention of GAN, the research community came up with several GAN architectures such as CycleGAN, DiscoGAN, DCGAN, with many other implementations. This project capitalizes on StyleGAN2 as the main GAN used.
StyleGAN
StyleGAN is an advanced model designed by NVIDIA to generate images in much higher and better quality. Before StyleGAN came to change the game in the world of generative models, most of the efforts toward improving the quality of GAN-generated images were focused on improving the discriminator through various techniques, such as using multiple discriminators, multi-resolution discrimination, or self-attention. This process is based on the idea that the better the discriminator, the more the generator will try to fool it, resulting in better-quality output. With all these improvements, the generator remains a black box.
“Yet the generators continue to operate as black boxes, and despite recent efforts, the understanding of various aspects of the image synthesis process, […] is still lacking. The properties of the latent space are also poorly understood.”
A Style-Based Generator Architecture for Generative Adversarial Networks
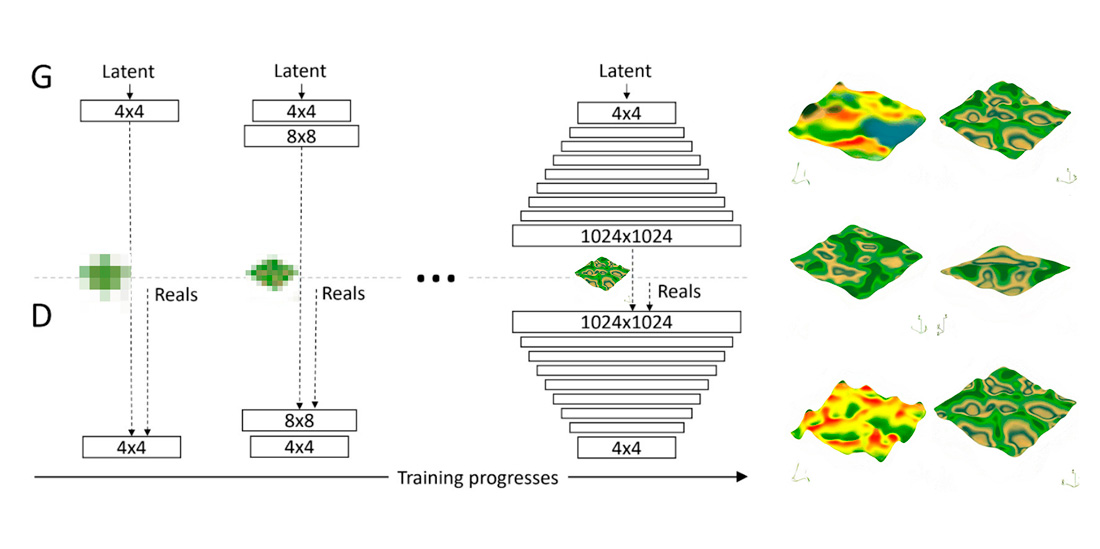
StyleGAN is based on the Progressive Growing GAN which is built to add layers incrementally in both the generator and discriminator as the training advances, increasing the spatial resolution of the generated images. Functionally, a crucial feature of StyleGANs, derived from PRO-GAN, is the speed of training, which allows further exploration using less time.
“[…] Another benefit is the reduced training time. With progressively growing GANs most of the iterations are done at lower resolutions, and comparable result quality is often obtained up to 2–6 times faster, depending on the final output resolution.”
Progressive Growing of GANs for Improved Quality, Stability, and Variation
As topographies have very complex details such as mountains, hills, valleys, creeks, etc. StyleGAN was used because it is capable of capturing and generating images that reflect these details.
Traditional vs. Style-based Generators
There are several differences between a StyleGAN generator, or a style-based generator, and a traditional one, taking the VanillaGAN as an example, for instance.
· The traditional generator feeds latent code immediately to input layers; while in StyleGAN, there is a mapping network that first maps the latent code to intermediate latent space, and it is represented as (w).
· The result from (w) space will be used as styles in adaptive instance normalization (AdaIN) operations at each resolution layer.
· The first layer in the generator is constant instead of a random variable.
· Stochastic noise is added pixel by pixel after each layer, which enables generating stochastic details (e.g., slopes and summits of topographies are considered stochastic aspects of topographies images).
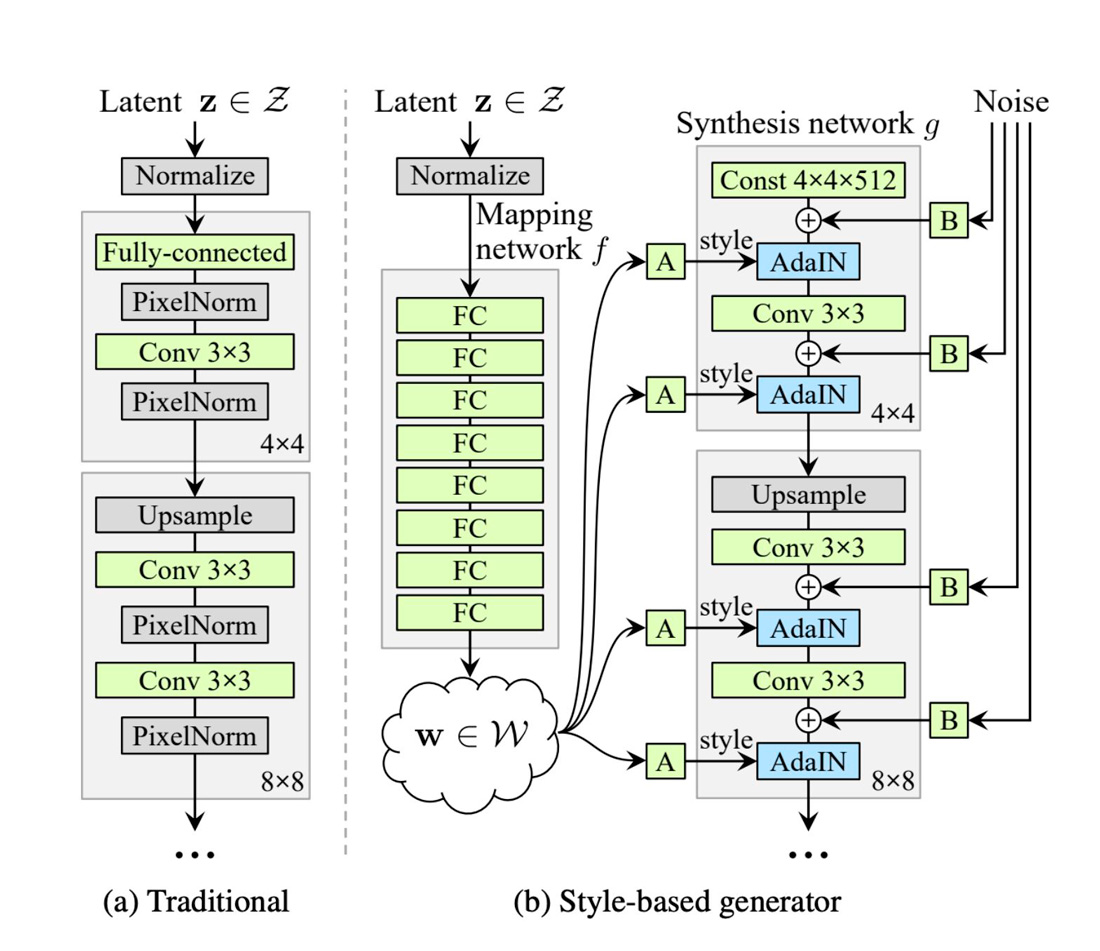
Source: A Style-Based Generator Architecture for Generative Adversarial Networks
Depth Maps, Truncation Trick & Dream Topographies
Aiming at generating daydream-brain-activity-infused topographies, training a StyleGAN was applied on a dataset of 1,000 (Black & White – 265 X 265) images where height is mapped to a domain of 0 (black) to 255 (white). This allows for reversible data compression, representing three-dimensional data in two-dimensional images, which then allows for generating high-quality synthetic depth maps.
First, the model was trained on Google Colab for several days using a single GPU and the NVLabs/StyleGAN implementation of StyleGAN for training.
Second, a dreamy aesthetic was injected into the generated topographies by adding a statistically calculated value, called the “dream factor” in this project, to the truncation trick value (truncation psi). The truncation trick allows for exploring the intermediate latent space (w) and choosing how close the generated images are to the average/normal distribution curve. Truncation psi value scales the deviation of w from the average, and as such can control the variety/quality tradeoff.
The dream factor is the sum of the mean of four channels from the temporoparietal [TP] and the Frontopolar [FP] (TP9, TP10, FP2, FP1] from a sample of the EEG dataset that was collected. Adding the dream factor to the truncation psi forces it to sample with more variety instead of quality.
“This technique allows fine-grained, post-hoc selection of the trade-off between sample quality and variety for a given G.”
Source: Large Scale GAN Training for High Fidelity Natural Image Synthesis
Code Sample
Calculating the “dream-factor”:
df = pd.read_csv(“musedata_daydreaming.csv”)
scaler = MinMaxScaler()
df[[‘RAW_TP9’, ‘RAW_TP10’, ‘RAW_FP2’, ‘RAW_FP1’]] = scaler.fit_transform(df[[‘RAW_TP9’, ‘RAW_TP10’, ‘RAW_FP2′ ,’RAW_FP1’]])
df.head()
def calculate_dream_factor():
return sum([df.RAW_TP10.mean() , df.RAW_TP9.mean(), df.RAW_FP2.mean(), df.RAW_FP1.mean()]) / 4
dream_factor = calculate_dream_factor()
truncation_psi = 1.5 + dream_factor
Truncation Thresholds
The effects of increasing truncation. From left to right, the threshold is set to 1 and 3
Less Dream-factor

More Dream-factor

Final Rendering
As demonstrated previously, the final artwork is a layered product of several techniques, where StyleGAN and a classic AI (agent system) are at the core. After producing the topographies, they are stacked and transformed into “food”, which active particles will steer towards. This steering happens buttom-up, while maintaining the trails to ensure visual connectivity between all the layers of the stack examined. Hence, the final aesthetic of the artwork is reminiscent of a brain wiring diagram, happening upon layers of dream-infused topographies of human and machine intelligence.











